AIの賢さも速さも手に入れる!MoEでWebサービスを次世代化する秘訣
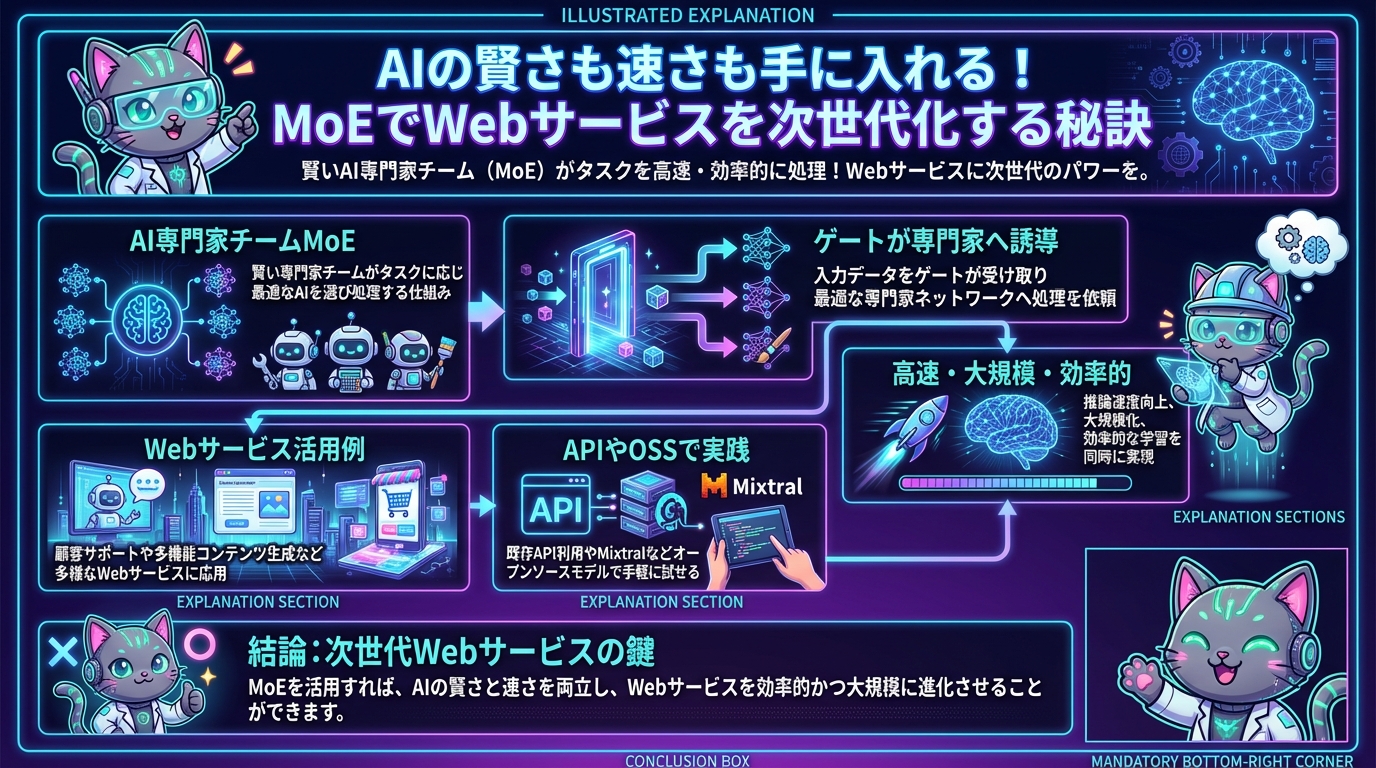
MoE(Mixture of Experts)って何? 賢さと速さの秘密
皆さん、こんにちは! 最先端の技術でWebサービスをゴリゴリ開発中のエンジニア、○○です。
最近、AIの進化がとどまるところを知りませんが、中でも特に注目されているのが「Mixture of Experts (MoE)」というアーキテクチャです。
「MoE?なんか難しそう…」と思ったあなた、ご安心ください!
簡単に言うと、MoEは「賢い専門家チーム」をAIモデルの中に作って、タスクに応じて最適な専門家を選んで仕事をさせる仕組みなんです。
これまでの大規模言語モデル(LLM)は、例えるなら「全部の科目に精通した万能の天才」のようなものでした。どんな質問に対しても、モデルの持つ全ての知識をフル稼働させて答えを出そうとします。これはこれで素晴らしいのですが、問題は計算コストがバカにならないこと。モデルが大きくなればなるほど、推論に時間がかかり、コストもかさみます。
そこでMoEの出番です!
MoEモデルは、内部にたくさんの小さな「専門家ネットワーク(Expert)」を持っています。そして、入力されたデータ(例えば、ユーザーからの質問)を「ゲート(Gate)」と呼ばれる部分が受け取り、「この質問は、あの翻訳の専門家チームに任せよう!」「これはコード生成の専門家チームだ!」というように、最適な専門家を選んで処理を依頼します。
つまり、毎回全てのパラメータを計算するのではなく、必要な専門家だけを呼び出すので、結果的に以下のメリットが生まれるんです。
- 圧倒的な大規模化が可能: 全体のパラメータ数は巨大にできるのに、推論時に動くのは一部なので、より多くの知識をモデルに詰め込めます。
- 推論速度の向上: 必要な部分だけを計算するため、同じ性能の万能モデルよりも高速に結果を返せます。
- 効率的な学習: 特定のタスクに特化した専門家を効率的に学習させることが可能になります。
これって、WebサービスやAI開発において、めちゃくちゃ強力な武器になりそうじゃないですか?
「これ使えそう!」Webサービス・AI開発での具体的な活用例
MoEの基本的な仕組みが分かったところで、私たち開発者がどう「使えそう!」とワクワクできるか、具体的な活用例を見ていきましょう。
Webサービスへの応用
- パーソナライズされた顧客サポートチャットボット
ユーザーの質問が「料金プランについて」ならプラン専門のAI、「技術的なトラブル」ならテクニカルサポート専門のAI、といった具合に、質問内容に応じて最適な専門家AIが応答します。
これにより、より的確でスピーディな解決を提供し、顧客満足度を爆上げできます。 - 多機能コンテンツ生成エンジン
ブログ記事生成、SNS投稿文作成、キャッチコピー考案など、コンテンツの種類に応じて最適な表現や情報を持つ専門家AIが執筆を担当します。
例えば、「SEOに強いブログ記事」の専門家、「SNSでバズる投稿」の専門家、のように切り替えることで、多様なニーズにきめ細かく対応できます。 - 多言語対応の効率化
グローバル展開するサービスにおいて、MoEモデル内に各言語に特化した翻訳専門家を配置すれば、より自然で高精度な翻訳を高速に提供できます。
言語ごとの微妙なニュアンスまで捉えた翻訳が期待できます。 - 動的なユーザーインターフェース生成
ユーザーの行動履歴やプロファイルに応じて、最適なUI要素やコンテンツを動的に生成する際にも活用できます。
例えば、「ECサイトで購買意欲の高いユーザーにはクーポン表示の専門家AIがデザインを担当」といったイメージです。
AI開発・LLMファインチューニング
- 自社特化型LLMの高性能化
特定の業界(医療、金融、法律など)に特化したLLMを開発する際、MoEアーキテクチャを採用することで、より多くの専門知識を効率的にモデルに組み込むことができます。
既存のMoEモデルをベースにファインチューニングすることで、少ない計算リソースで高い専門性を実現できる可能性があります。 - エッジデバイスでのAI推論の効率化
スマートデバイスやIoT機器など、リソースが限られた環境でAIを動かす場合、MoEの「必要な専門家だけを使う」特性は非常に有利です。
特定のタスクに特化させることで、軽量かつ高速な推論が可能になります。 - マルチモーダルAIへの応用
画像、テキスト、音声など、複数のモダリティ(情報形式)を扱うAIモデルにおいて、それぞれのモダリティ処理に特化した専門家を配置することで、より複雑で高度な認識・生成能力を持たせることができます。
例えば、画像解析の専門家とテキスト生成の専門家が連携して、画像から詳細な説明文を生成する、といったことが考えられます。
さあ、MoEを試してみよう!最初の一歩はここから
「MoE、面白そう! 自分のプロジェクトにも取り入れたい!」と感じたあなた、素晴らしいです!
いきなりゼロからMoEモデルを構築するのは大変ですが、今からでも手軽に試せる方法はたくさんあります。
1. 既存のMoEモデルAPIを試す
現在、OpenAIのGPT-4VやGoogleのGemini Advancedなど、高性能なLLMの多くは内部的にMoEアーキテクチャを採用していると言われています。
これらのAPIを利用するだけでも、MoEの恩恵(高速な応答、多様なタスクへの対応能力)を間接的に体験できます。
まずは、現在利用しているAIモデルのAPIドキュメントを読み込んで、最新の機能やパフォーマンスをチェックしてみましょう。
2. オープンソースのMoEモデルを動かしてみる
Hugging Faceなどのプラットフォームでは、Mixtral 8x7Bのような強力なオープンソースのMoEモデルが公開されています。
これらを自分の環境(ローカルPC、Google Colab、クラウドGPUなど)で動かして、その性能を体感するのが一番の近道です。
Mixtral 8x7Bを試すなら
- Hugging Face Transformersライブラリを使えば、Pythonで数行のコードを書くだけで簡単に推論を試せます。
まず、pip install transformers accelerateで必要なライブラリをインストールします。 - Pythonでの簡単な例:
from transformers import AutoTokenizer, AutoModelForCausalLM import torch tokenizer = AutoTokenizer.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1") model = AutoModelForCausalLM.from_pretrained("mistralai/Mixtral-8x7B-Instruct-v0.1 やってみよう MoE(Mixture of Experts)の仕組みを理解するため、まずは簡単なルーティング機能を実装してみましょう。ここでは、入力されたテキストの種類に応じて、適切な「専門家」を選択する基本的なMoEシミュレーターを作成します。 # 簡単なMoEルーティングの実装 import random class SimpleExpert: def __init__(self, name, specialty): self.name = name self.specialty = specialty def process(self, input_text): return f"{self.name}が処理: {input_text[:50]}..." # 専門家を作成 experts = [ SimpleExpert("技術専門家", "programming"), SimpleExpert("文章専門家", "writing"), SimpleExpert("数学専門家", "math") ] def route_to_expert(input_text): # 簡単なルーティングロジック if any(word in input_text.lower() for word in ["code", "python", "javascript"]): return experts[0] elif any(word in input_text.lower() for word in ["計算", "数式", "math"]): return experts[2] else: return experts[1] # テスト test_input = "Pythonでループを書く方法を教えて" selected_expert = route_to_expert(test_input) print(selected_expert.process(test_input)) 🛠 作ってみよう: MoE風タスク振り分けCLIツール ⏱ 所要時間: 約25分 | 🟡中級 前提条件 Python 3.8以上がインストール済み 基本的なPythonの知識 ターミナル/コマンドプロンプトの基本操作 完成イメージ ユーザーが入力したタスクを解析し、最適な「専門家AI」を選択して処理を振り分けるCLIツールを作成します。実際のAIは使わず、各専門家の特徴的な応答をシミュレートします。 Step 1: 基本構造を作成 まず、専門家クラスとルーティング機能を含むメインファイルを作成します。 #!/usr/bin/env python3 # moe_cli.py import argparse import re from typing import List, Dict from dataclasses import dataclass @dataclass class Expert: name: str specialty: str keywords: List[str] response_template: str class MoERouter: def __init__(self): self.experts = [ Expert( name="CodeMaster", specialty="プログラミング", keywords=["code", "python", "javascript", "bug", "関数", "プログラム"], response_template="🔧 {name}: コードの問題ですね。{specialty}の観点から分析します..." ), Expert( name="DataAnalyst", specialty="データ分析", keywords=["data", "分析", "統計", "グラフ", "csv", "database"], response_template="📊 {name}: データの課題ですね。{specialty}の手法で解決しましょう..." ), Expert( name="WritingPro", specialty="文章作成", keywords=["文章", "記事", "ブログ", "文書", "レポート", "writing"], response_template="✍️ {name}: 文章に関するタスクですね。{specialty}のスキルを活用します..." ), Expert( name="GeneralHelper", specialty="一般サポート", keywords=[], response_template="🤖 {name}: 幅広い{specialty}でお手伝いします..." ) ] def route(self, task: str) -> Expert: task_lower = task.lower() scores = {} for expert in self.experts[:-1]: # 最後の一般サポート以外 score = sum(1 for keyword in expert.keywords if keyword in task_lower) if score > 0: scores[expert] = score if scores: return max(scores.items(), key=lambda x: x[1])[0] else: return self.experts[-1] # 一般サポート Step 2: CLI機能を実装 コマンドライン引数の処理と対話機能を追加します。 # moe_cli.py に追加 def simulate_processing(expert: Expert, task: str) -> str: """専門家による処理をシミュレート""" response = expert.response_template.format( name=expert.name, specialty=expert.specialty ) # 専門家別の具体的な応答例 if "Code" in expert.name: response += f"\n\n具体的な提案:\n- コードレビューを実施\n- デバッグ手順を提示\n- ベストプラクティスを適用" elif "Data" in expert.name: response += f"\n\n分析アプローチ:\n- データの前処理\n- 可視化による洞察\n- 統計的検証" elif "Writing" in expert.name: response += f"\n\n文章改善案:\n- 構成の最適化\n- 読みやすさの向上\n- トーン調整" else: response += f"\n\n総合的なサポート:\n- 問題の整理\n- 解決策の提案\n- 次のステップの明確化" return response def main(): parser = argparse.ArgumentParser(description='MoE風タスク振り分けツール') parser.add_argument('--interactive', '-i', action='store_true', help='対話モード') parser.add_argument('task', nargs='?', help='処理したいタスク') args = parser.parse_args() router = MoERouter() if args.interactive: print("🚀 MoE タスク振り分けツール (対話モード)") print("終了するには 'quit' と入力してください\n") while True: task = input("タスクを入力してください: ").strip() if task.lower() in ['quit', 'exit', 'q']: print("お疲れさまでした!") break if task: expert = router.route(task) print(f"\n選択された専門家: {expert.name}") print("=" * 50) print(simulate_processing(expert, task)) print("=" * 50 + "\n") elif args.task: expert = router.route(args.task) print(f"選択された専門家: {expert.name}") print("=" * 50) print(simulate_processing(expert, args.task)) else: parser.print_help() if __name__ == "__main__": main() Step 3: 実行とテスト 作成したツールを実際に動かしてテストします。 # 実行権限を付与(Linux/Mac) chmod +x moe_cli.py # 単発実行のテスト python moe_cli.py "Pythonでバグを修正したい" python moe_cli.py "売上データを分析して欲しい" python moe_cli.py "ブログ記事を書きたい" # 対話モードで実行 python moe_cli.py --interactive カスタマイズのヒント 専門家の追加: `experts`リストに新しい専門分野を追加できます。例:「デザイン専門家」「マーケティング専門家」など ルーティングロジックの改良: キーワードマッチングだけでなく、文章の長さや質問の種類(疑問文、命令文)も考慮したスコアリング機能を実装 履歴機能: 過去のタスクと選択された専門家の履歴をJSONファイルに保存し、学習効果をシミュレートする機能を追加


