Geminiが拓く次世代Webと画像生成AI:開発者のための実践ガイド
皆さん、こんにちは!Web制作とAI開発の最前線を追いかけるエンジニアの皆さん、今日のテーマはちょっと刺激的ですよ。
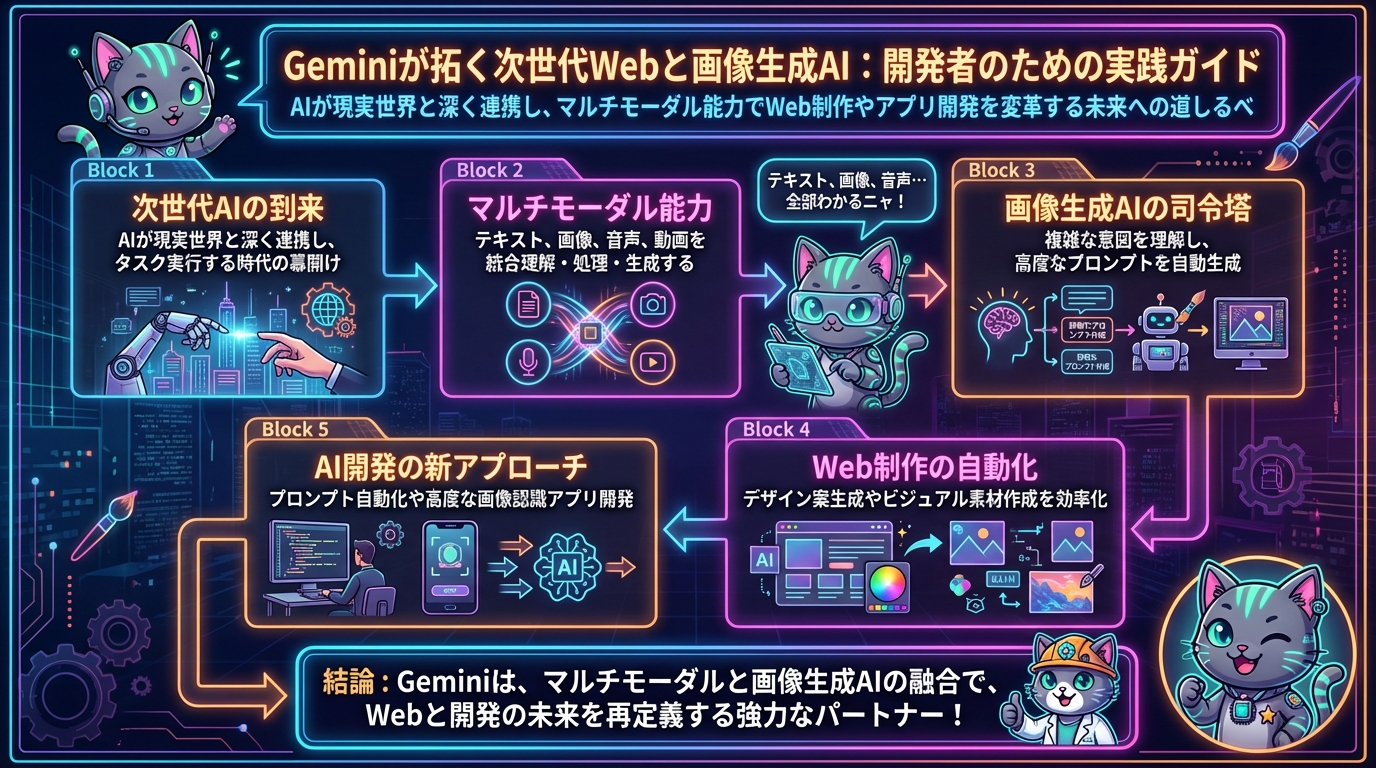
最近、「Google GeminiがPixel 10やGalaxy S26でUberの予約やフードの注文を直接実行できる」というニュースが駆け巡りましたね。これを聞いて、「へぇ、便利になったね」で終わっていませんか?いやいや、ちょっと待ってください。これは単なるスマートフォンの新機能というレベルの話ではありません。AIが私たちの現実世界と、より深く、より実用的に連携し始める時代の到来を告げているんです。
特に、我々開発者・Web制作者にとって、このGeminiの進化は「画像生成AI」の分野、そしてWebサイトやアプリケーションの構築方法に、とてつもない可能性をもたらします。今日は、Geminiのマルチモーダルな能力が、どのように私たちのクリエイティブなプロセスを変革し、新しいビジネスチャンスを生み出すのかを深掘りしていきましょう。「これ使えそう!」「試してみよう」と思ってもらえるような、実践的な視点でお話ししますね。
Geminiのマルチモーダル能力とは?何ができるのか
まず、Geminiの核となる特徴は、その「マルチモーダル」な能力にあります。これは、テキスト、画像、音声、動画といった、様々な形式の情報を同時に理解し、それらを組み合わせて処理し、さらに新しい情報を生成できるという、まさに次世代のAIであることを意味します。
例えば、元ネタにある「Uber予約やフード注文」は、ユーザーの「お腹が空いたからピザを注文してほしい」という音声指示をテキストに変換し、その意図を理解し、さらに外部のフードデリバリーサービスと連携してタスクを実行するという、一連のマルチモーダルな処理の賜物です。これは単にチャットボットが応答するのとは次元が違う、「タスク実行能力」の顕れなんです。
では、これが画像生成AIとどう繋がるのでしょうか?
- より高度な画像生成プロンプトの作成: Geminiは、単なるキーワードの羅列ではなく、ユーザーの複雑な意図や文脈、さらには感情までを理解し、それを画像生成AI(Stable DiffusionやMidjourneyなど)が理解しやすい、詳細かつ的確なプロンプトに変換できます。例えば、「このWebサイトのデザインコンセプトに合うような、都会的で洗練された雰囲気の背景画像を生成して」といった、曖昧ながらも意図の深い指示から、具体的なプロンプトを生成できるわけです。
- 画像とテキストの相互理解: Geminiは、既存の画像を見てその内容を理解し、説明を生成するだけでなく、その画像に対する修正指示(例:「この画像の空をもっと夕焼けっぽくして」)を理解し、画像生成AIに指示を出すことができます。これにより、よりインタラクティブな画像編集や生成が可能になります。
- 多角的な情報からの画像生成: テキストだけでなく、音声や他の画像データ、さらにはWeb上の情報など、複数のソースから得た情報を統合して、全く新しい画像を生成することも夢ではありません。例えば、あるブランドのコンセプト動画とテキスト情報から、そのブランドに最適な広告画像を自動生成するといった応用が考えられます。
つまり、Geminiは単体で画像を生成するだけでなく(もちろんその能力も持っていますが)、既存の画像生成AIの「司令塔」として機能することで、その可能性を何倍にも広げる存在なんです。
開発者・Web制作者はどう使えるのか?具体的な活用例
このGeminiのマルチモーダル能力は、Web制作とAI開発の現場に革命をもたらす可能性を秘めています。具体的な活用例をいくつか見ていきましょう。
Web制作の自動化・効率化
- デザイン案の自動生成と調整:
「新しいECサイトのトップページデザインが欲しい。ターゲットは20代女性で、シンプルかつ高級感のあるイメージ。商品はコスメ。」といった指示をGeminiに与えるだけで、ワイヤーフレームや具体的なデザイン案の画像を複数生成させることができます。さらに、「このデザインの背景色をもう少し明るくして」「ここに商品画像を配置して」といった修正指示も、自然言語でAIに伝え、リアルタイムでデザイン調整を進められます。 - コンテンツに合わせたビジュアル素材の生成:
ブログ記事やWebサイトのテキストコンテンツから、その内容に最適なアイキャッチ画像や挿絵を自動生成。記事の更新と同時に、関連性の高いビジュアルコンテンツも用意されるため、コンテンツ制作のリードタイムが大幅に短縮されます。 - パーソナライズされたUI/UXの実現:
ユーザーの行動履歴やプロファイル、さらにはデバイス情報に基づいて、個々のユーザーに最適化されたバナー広告、商品画像、UIエレメントをリアルタイムで生成・表示。たとえば、特定のユーザーが関心を示している商品カテゴリのビジュアルを強調したり、季節やイベントに合わせたデザイン要素を自動で組み込んだりすることが可能です。 - A/Bテスト用のクリエイティブ作成:
複数のデザインバリエーションやコピーを組み合わせた広告バナーやWebサイトのセクション画像を、Geminiが自動で生成。これにより、手作業でのクリエイティブ作成にかかる時間を削減し、より多くのテストパターンを迅速に試すことができます。
AI開発の新しいアプローチ
- プロンプトエンジニアリングの自動化・最適化:
画像生成AIを扱う上で最も重要な「プロンプト」の作成をGeminiが支援。ユーザーの漠然としたアイデアから、詳細で効果的なプロンプトを生成し、希望通りの画像を効率的に生み出すことができます。これにより、プロンプト作成の専門知識がなくても、高品質な画像を生成しやすくなります。 - 画像認識と生成の連携による高度なアプリケーション:
ユーザーが手書きで描いたスケッチ画像をGeminiが認識し、その意図を汲み取って高精細なイラストやデザイン画像に変換するアプリケーション。例えば、建築家が手書きで描いた間取り図から、リアルな3Dパース画像を生成するシステムなどに応用できます。 - マルチモーダルデータセットの構築支援:
AIモデルの学習に必要な多様なデータセット(画像、テキスト、音声など)を、Geminiが効率的に収集・整理・アノテーションする作業を支援。これにより、よりリッチで高品質な学習データセットを迅速に準備できます。 - クリエイティブなAIアシスタントの開発:
小説の執筆中に、特定のシーン描写から登場人物や背景のイラストを自動生成したり、ゲーム開発において、キャラクター設定や世界観の説明からゲームアセット(テクスチャ、モデルの概念図など)を生成したりする、新しい形のクリエイティブアシスタントを開発できます。
これらはほんの一部に過ぎません。Geminiのマルチモーダル能力と画像生成AIの組み合わせは、まさに無限の可能性を秘めていると言えるでしょう。
試すならどこから始めるか?実践への第一歩
さて、ここまで読んで「よし、試してみよう!」と思った開発者・Web制作者の皆さんのために、どこから手をつければ良いか、具体的なステップをいくつかご紹介します。
- Google AI Studio / Vertex AIの活用:
まずは、Googleが提供するGoogle AI StudioやVertex AIにアクセスしましょう。ここでGemini APIに触れ、そのマルチモーダル機能を実際に体験できます。テキストと画像を同時に扱うプロンプトを試したり、Geminiがどのように画像を解釈し、応答を生成するかを確認したりするのが第一歩です。画像生成機能も提供されているので、基本的な画像生成も試せます。 - 既存の画像生成AIとの連携シナリオを検討:
すでにStable DiffusionやMidjourneyなどの画像生成AIを使っている方は、それらのAPIをGeminiと組み合わせて使うシナリオを考えてみましょう。例えば、「ユーザーがWebサイトで求めている特定のイメージ(自然言語)をGeminiが解釈し、最適なプロンプトを生成。そのプロンプトをStable Diffusion APIに渡し、生成された画像をWebサイトに動的に表示する」といったワークフローを構築してみるのが良いでしょう。 - Webアプリケーションへの組み込みを試す:
Google AI Studioで作成したプロトタイプを、JavaScriptやPythonなどの言語を使って、実際のWebアプリケーションに組み込んでみましょう。ユーザーインターフェースをどう設計するか、AIが生成した画像をどのように表示し、ユーザーがフィードバックを与えられるようにするかなど、具体的なUI/UXを検討しながら進めることで、より実践的な知見が得られます。 - 学習リソースの活用とコミュニティ参加:
Google Developersの公式ドキュメントは、Gemini APIの機能や使い方を学ぶ上で不可欠です。また、GitHubやStack Overflow、DiscordなどのAI開発コミュニティに参加し、他の開発者と情報交換を行うことで、新しいアイデアや解決策が見つかることもあります。
Geminiの登場は、AIが単なるツールから、私たちのクリエイティブなプロセスにおける強力な「共同制作者」へと進化する転換点を示しています。Web制作とAI開発の未来を形作るこの波に乗り遅れないよう、ぜひ今日からその可能性を探求し始めてください。皆さんの手で、次世代のWebとAI体験が生まれることを楽しみにしています!


