GPT-5.2級LLMを自社に!Qwen3-32BベースでオンプレAIを動かす戦略
みずほFGの事例から学ぶ!GPT-5.2級LLMを自社で運用する衝撃
皆さん、こんにちは!Web制作とAI開発の最前線を追いかけるエンジニアの皆さん、今日のニュースは要チェックですよ。
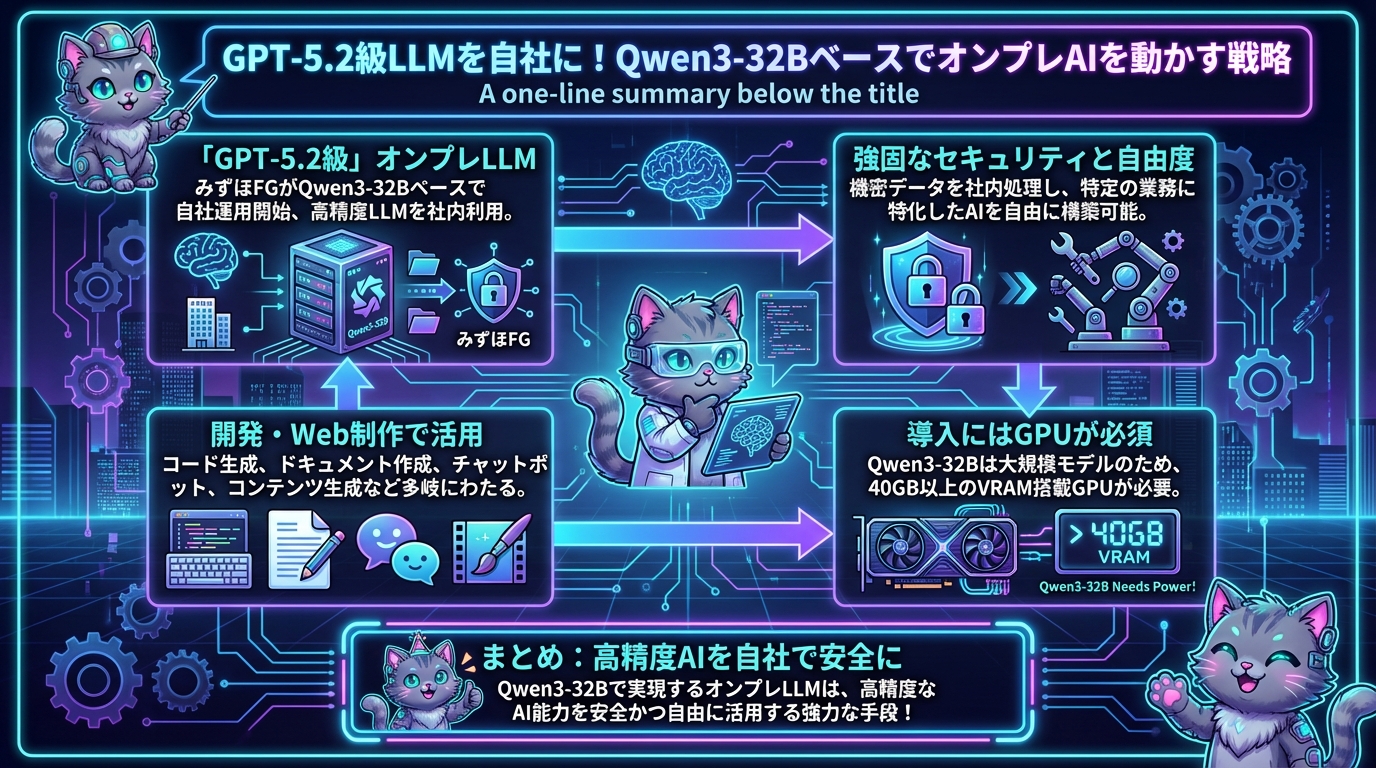
先日、金融業界の巨人、みずほフィナンシャルグループが「GPT-5.2と同精度」の自社LLMをオンプレミスで運用開始という驚きの発表がありました。しかもそのベースは、オープンソースの強力なモデル「Qwen3-32B」だというから、これは見過ごせません。
「え、GPT-5.2級が社内で動くの?」「オープンソースでそんな精度が出せるの?」と、多くの開発者やWeb制作者の皆さんもざわついたのではないでしょうか。このニュースは、単なる企業の取り組みというだけでなく、私たち開発者がLLMをどう活用し、どうビジネスに組み込んでいくかの未来を大きく示唆しています。特に、コスト、セキュリティ、そしてカスタマイズ性という点で、既存のクラウドAPI型LLMに課題を感じていた方々にとっては、まさに待望の選択肢となる可能性を秘めているのです。
今日は、この「Qwen3-32B」ベースのオンプレミスLLMが「何ができるのか」「どう使えるのか」、そして「試すならどこから始めるべきか」を深掘りし、皆さんの次のプロジェクトに役立つヒントをお届けします!
何ができるのか?「GPT-5.2級」の性能をオンプレで手に入れるメリット
みずほFGが「GPT-5.2と同精度」と表現するほどの性能を持つLLMを、自社環境で動かすことには、計り知れないメリットがあります。
- 驚異的な精度と汎用性:「GPT-5.2級」という表現は、現在の最先端AIモデルに匹敵する、あるいはそれを超えるような高度な言語理解・生成能力を持つことを示唆しています。これにより、複雑な文書の要約、高度な質問応答、自然な文章生成、多言語翻訳など、幅広いタスクを高精度でこなすことが期待できます。
- 強固なセキュリティとデータガバナンス:最大のメリットの一つは、機密性の高いデータを外部に送ることなく、社内ネットワーク内で処理を完結できる点です。金融機関であるみずほFGがオンプレミスを選んだのも、このセキュリティが最重要視されたためでしょう。個人情報や企業秘密、顧客データなど、センシティブな情報を扱うWebサービスや社内システムにとって、これは絶対的な安心材料となります。
- コスト最適化の可能性:クラウドLLMのAPI利用は、リクエスト量に応じて課金されるため、利用が拡大するほどコストも膨らみます。しかし、オンプレミスであれば、初期投資はかかるものの、長期的に見れば運用コストを大幅に削減できる可能性があります。特に大規模な利用が見込まれる場合、この差は非常に大きくなります。
- 圧倒的なカスタマイズ性:自社でモデルを運用するということは、特定の業務やドメインに特化したファインチューニングを自由に行えることを意味します。これにより、汎用モデルでは対応しきれないニッチな専門知識や、企業独自の表現スタイル、用語などを学習させ、より精度の高い、自社に最適化されたAIを作り上げることが可能になります。
- 低レイテンシと安定性:社内ネットワーク内で処理を行うため、インターネット回線の影響を受けにくく、低レイテンシで安定した応答速度を実現できます。これは、リアルタイム性が求められるシステムや、ユーザー体験を重視するWebサービスにおいて非常に重要です。
これらのメリットを享受できるのが、オープンソースの高性能モデル「Qwen3-32B」ベースのオンプレミスLLMというわけです。Qwen3はAlibaba Cloudが開発した強力なモデルで、多言語対応もしており、そのポテンシャルは計り知れません。
どう使えるのか?開発者・Web制作者のための具体的な活用例
では、このQwen3-32BベースのオンプレミスLLMを、私たち開発者やWeb制作者は具体的にどう活用できるでしょうか?
開発現場での活用
- コード生成・レビュー支援:社内のコーディング規約に沿ったコードスニペットの生成、既存コードの脆弱性チェック、リファクタリング提案など。機密性の高い独自コードも安心して分析させられます。
- ドキュメント自動生成:設計書やAPIドキュメント、テスト仕様書など、開発プロセスの各段階で必要なドキュメントの叩き台を自動生成。
- テストケース自動生成:既存のコードや仕様書から、網羅性の高いテストケースを自動で作成。
- 社内FAQ・ナレッジベース検索:社内システムの操作方法や過去の障害対応ログなど、散在する情報を瞬時に検索・要約し、開発者の生産性向上に貢献。
Webサービス・コンテンツ制作での活用
- パーソナライズされたコンテンツ生成:ユーザーの閲覧履歴や行動パターンに基づき、ブログ記事、SNS投稿、メールマガジンの文章などを自動生成し、エンゲージメントを高める。
- 高度なカスタマーサポートチャットボット:ユーザーの複雑な問い合わせに対し、高精度で自然な対話を実現。自社製品・サービスに関する詳細な知識を学習させ、より専門的なサポートを提供。
- Webサイトの多言語対応支援:サイトコンテンツの自動翻訳や、多言語でのFAQ生成など、グローバル展開を加速させるツールとして。
- SEOコンテンツの最適化:キーワード分析に基づいた記事タイトル、メタディスクリプション、本文の生成支援。
- ユーザーフィードバック分析:レビューやアンケートから、ユーザーの意見や感情を抽出し、製品・サービス改善のためのインサイトを導き出す。
これらの活用例はほんの一部に過ぎません。自社のビジネスモデルやWebサービスに合わせて、無限の可能性を探ることができます。
試すならどこから始めるか?Qwen3-32B導入のステップ
「よし、Qwen3-32Bを試してみよう!」と思った方のために、導入の第一歩となるポイントを解説します。
1. ハードウェア要件の確認
Qwen3-32Bは320億パラメータという大規模モデルです。これを動かすには、それなりのGPUメモリが必要になります。一般的には、40GB以上のVRAMを搭載したGPU(例:NVIDIA A100/H100, RTX 6000 Adaなど)が推奨されます。まずは、手元の環境で動かせるか、クラウドサービス(AWS EC2, Google Cloud VM, Azure VMなど)で適切なインスタンスを選定できるかを確認しましょう。
2. 環境構築とモデルのダウンロード
- Python環境の準備:最新のPythonと、必要なライブラリ(
transformers,torchなど)をインストールします。 - Hugging Face Transformers:Qwen3はHugging Face Hubで公開されています。
transformersライブラリを使えば、簡単にモデルをロードできます。pip install transformers torch accelerate - モデルのダウンロード:Hugging Face HubからQwen3-32Bモデルをダウンロードします。かなりのサイズになるため、安定したネットワーク環境が必要です。
3. 推論の実行
モデルをロードしたら、簡単なテキスト生成を試してみましょう。Pythonスクリプトで数行書くだけで、Qwen3-32Bの強力な能力を体験できます。
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-32B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
prompt = "AI技術の最新トレンドについて教えてください。"
messages = [{"role": "user やってみよう まずはQwen3-32Bモデルを実際に体験してみましょう。Hugging Faceのtransformersライブラリを使って、簡単にローカル環境で動作確認できます。GPT-5.2級の性能を手軽に試せるのが魅力です。 # 必要なライブラリをインストール pip install transformers torch accelerate # Qwen3-32Bを使った簡単なテスト from transformers import AutoTokenizer, AutoModelForCausalLM import torch model_name = "Qwen/Qwen2.5-32B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto" ) # テスト実行 prompt = "Python でWebスクレイピングのコードを書いて" inputs = tokenizer(prompt, return_tensors="pt") outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response) このコードで実際にGPT-5.2級の応答品質を確認できます。ただし32Bモデルは大容量なので、十分なGPUメモリ(24GB以上推奨)が必要です。 🛠 作ってみよう: オンプレLLMチャットボットAPI ⏱ 所要時間: 約45分 | 🟡中級 前提条件 Python 3.8以上 CUDA対応GPU(VRAM 16GB以上推奨) FastAPI、transformersの基本知識 完成イメージ Qwen3-32BベースのREST APIサーバーを構築し、Webブラウザから直接チャットできるシンプルなインターフェースを作成します。みずほFGのような本格的なオンプレミスLLM運用の第一歩となるシステムです。 Step 1: 環境セットアップとAPI基盤構築 まずは必要なパッケージをインストールし、FastAPIベースのサーバーを構築します。 # 依存関係のインストール pip install fastapi uvicorn transformers torch accelerate pydantic # app.py from fastapi import FastAPI, HTTPException from fastapi.middleware.cors import CORSMiddleware from fastapi.responses import HTMLResponse from pydantic import BaseModel from transformers import AutoTokenizer, AutoModelForCausalLM import torch import logging # ログ設定 logging.basicConfig(level=logging.INFO) logger = logging.getLogger(__name__) app = FastAPI(title="オンプレLLM API", version="1.0.0") # CORS設定 app.add_middleware( CORSMiddleware, allow_origins=["*"], allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) # リクエストモデル class ChatRequest(BaseModel): message: str max_length: int = 500 # グローバル変数でモデルを保持 tokenizer = None model = None @app.on_event("startup") async def load_model(): global tokenizer, model logger.info("モデル読み込み開始...") model_name = "Qwen/Qwen2.5-32B-Instruct" tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained( model_name, torch_dtype=torch.float16, device_map="auto", trust_remote_code=True ) logger.info("モデル読み込み完了!") Step 2: チャット機能とWeb UIの実装 LLMとの対話機能を実装し、ブラウザから使えるシンプルなUIも追加します。 # app.py に追加 @app.post("/chat") async def chat_endpoint(request: ChatRequest): try: if not model or not tokenizer: raise HTTPException(status_code=503, detail="モデルが読み込まれていません") # プロンプト構築 system_prompt = "あなたは親切で知識豊富なAIアシスタントです。" full_prompt = f"system\n{system_prompt}\nuser\n{request.message}\nassistant\n" # トークン化 inputs = tokenizer(full_prompt, return_tensors="pt") # 生成 with torch.no_grad(): outputs = model.generate( **inputs, max_length=len(inputs.input_ids[0]) + request.max_length, temperature=0.7, do_sample=True, pad_token_id=tokenizer.eos_token_id ) # レスポンス抽出 response = tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True) return { "response": response.strip(), "model": "Qwen3-32B", "status": "success" } except Exception as e: logger.error(f"エラー発生: {str(e)}") raise HTTPException(status_code=500, detail=str(e)) @app.get("/", response_class=HTMLResponse) async def get_chat_ui(): html_content = """ 🤖 オンプレLLMチャット (Qwen3-32B)
送信 """ return html_content @app.get("/health") async def health_check(): return {"status": "healthy", "model_loaded": model is not None}
Step 3: サーバー起動と動作確認
完成したAPIサーバーを起動し、ブラウザから動作確認を行います。
# サーバー起動
uvicorn app:app --host 0.0.0.0 --port 8000 --reload
# 別ターミナルでAPIテスト
curl -X POST "http://localhost:8000/chat" \
-H "Content-Type: application/json" \
-d '{"message": "Pythonでファイル読み込みのサンプルコードを教えて"}'
ブラウザで http://localhost:8000 にアクセスすると、チャットUIが表示されます。モデルの読み込みには数分かかる場合があるので、/health エンドポイントで状態を確認してください。
カスタマイズのヒント
メモリ最適化: load_in_8bit=True や load_in_4bit=True を追加してVRAM使用量を削減できますセキュリティ強化: API キー認証やレート制限を追加して本格運用に備えましょうログ機能: 会話履歴をデータベースに保存し、学習データとして活用する仕組みを構築できます


